
在数字经济高速发展的今天,软件早已超越技术工具的角色,成为企业核心资产与创新成果的重要载体。然而,软件知识产权保护长期面临“举证难、鉴定慢、成本高、专业门槛高”四大痛点。传统司法鉴定依赖人工比对与静态特征提取,难以应对海量代码、跨语言、跨平台等复杂场景,更无法匹配敏捷开发与快速迭代的时代节奏。
现在,这一困局即将被彻底打破。
我们隆重推出——“智鉴”软件源代码知识产权司法鉴定平台,首个完全由大模型驱动的智能化司法鉴定系统。以AI之力,为软件创新保驾护航,让每一段代码的价值都被看见、被尊重、被保护。
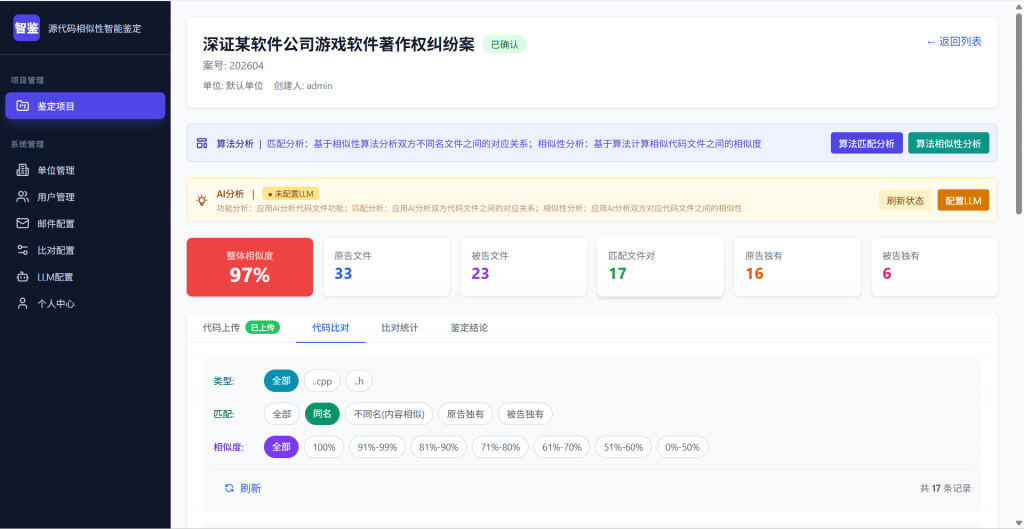
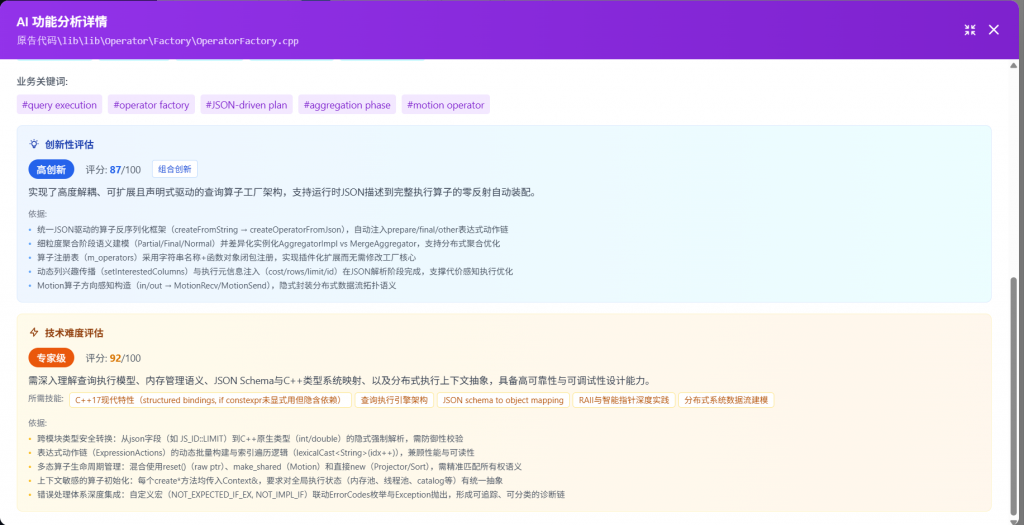
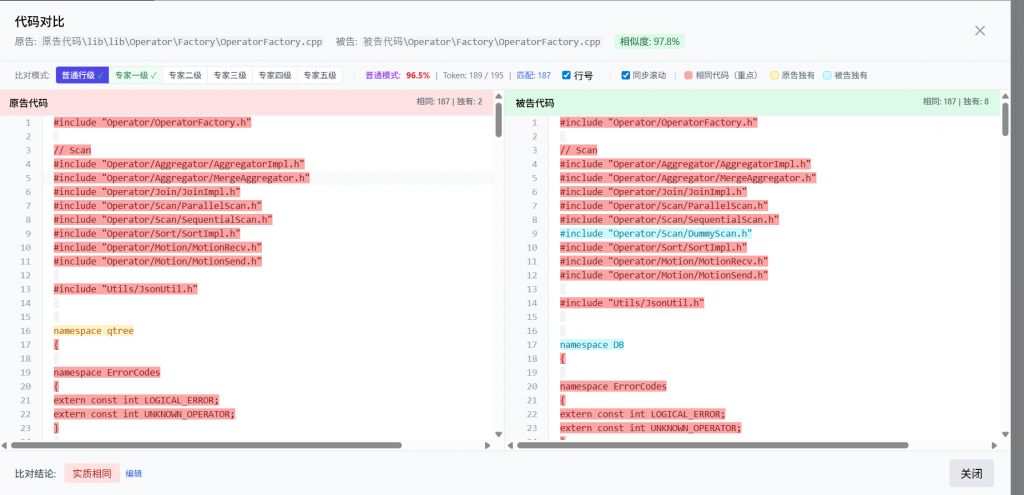
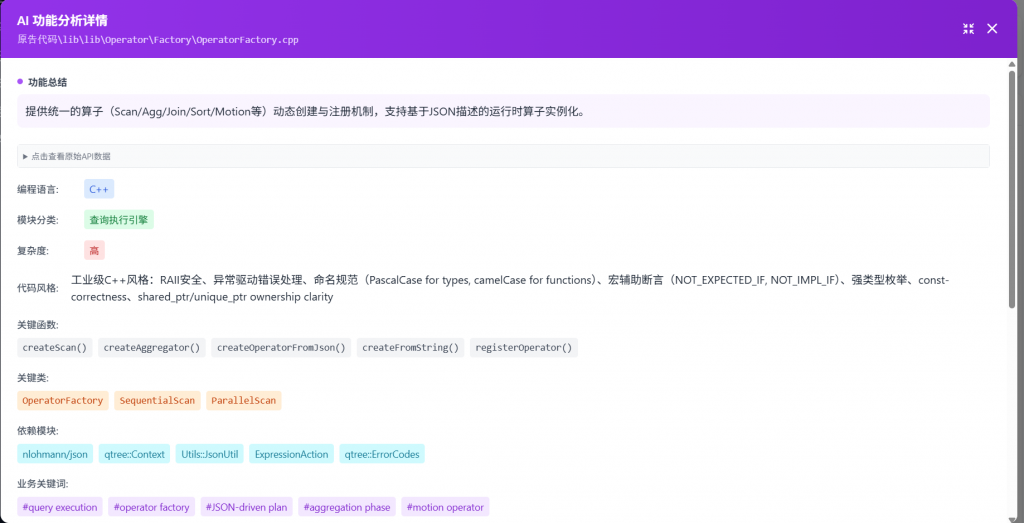
为什么需要“智鉴代码”?
- 传统方法“看得见表象,读不懂语义”
现有工具仅能比对字符串、函数名或二进制指纹,面对代码重构、逻辑抄袭、算法盗用等“高阶侵权”行为束手无策。 - 人工分析效率低、主观性强
专家手动比对动辄耗时数周,成本高昂,且结论易受经验与主观判断影响,难以满足司法对客观性与一致性的要求。 - 大模型时代,鉴定亟需“认知升级”
代码不仅是字符序列,更是逻辑、意图与设计思想的表达。“智鉴代码”让大模型真正“读懂”代码,实现从“字符匹配”到“语义理解”的范式跃迁。
全大模型驱动,重新定义司法鉴定
“智鉴代码”基于自研的代码认知大模型(Code-Cognition LLM),深度融合软件工程、编译原理与司法鉴定逻辑,构建端到端的自动化智能鉴定引擎:
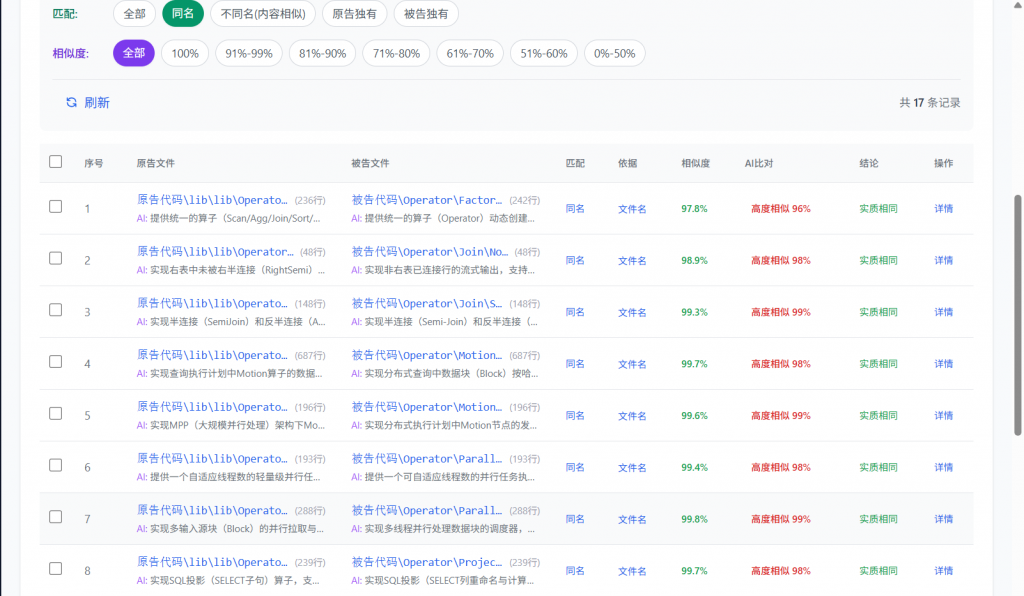
- 语义级代码比对
突破语法差异与命名习惯,精准识别代码背后的逻辑意图。即使代码经过重命名、结构重构,甚至跨语言重写,也能有效发现“换皮不换心”的实质性相似。 - 跨平台、跨编译器分析能力
支持源码与二进制混合比对,兼容主流编译器及不同优化级别,破解“仅有可执行文件、无源代码”的鉴定难题。 - 智能提取设计特征与数字指纹
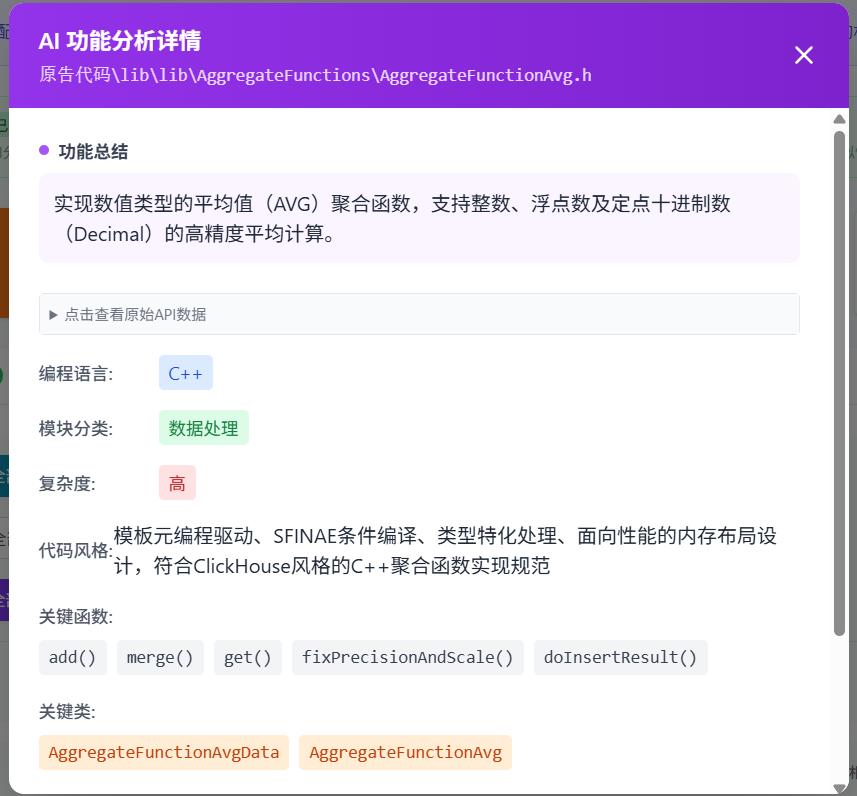
自动识别代码中的独特缺陷、冗余逻辑、编码风格等“数字DNA”,辅助判断代码同源性与开发路径,提升证据链完整性。 - 可解释、可质证的鉴定报告
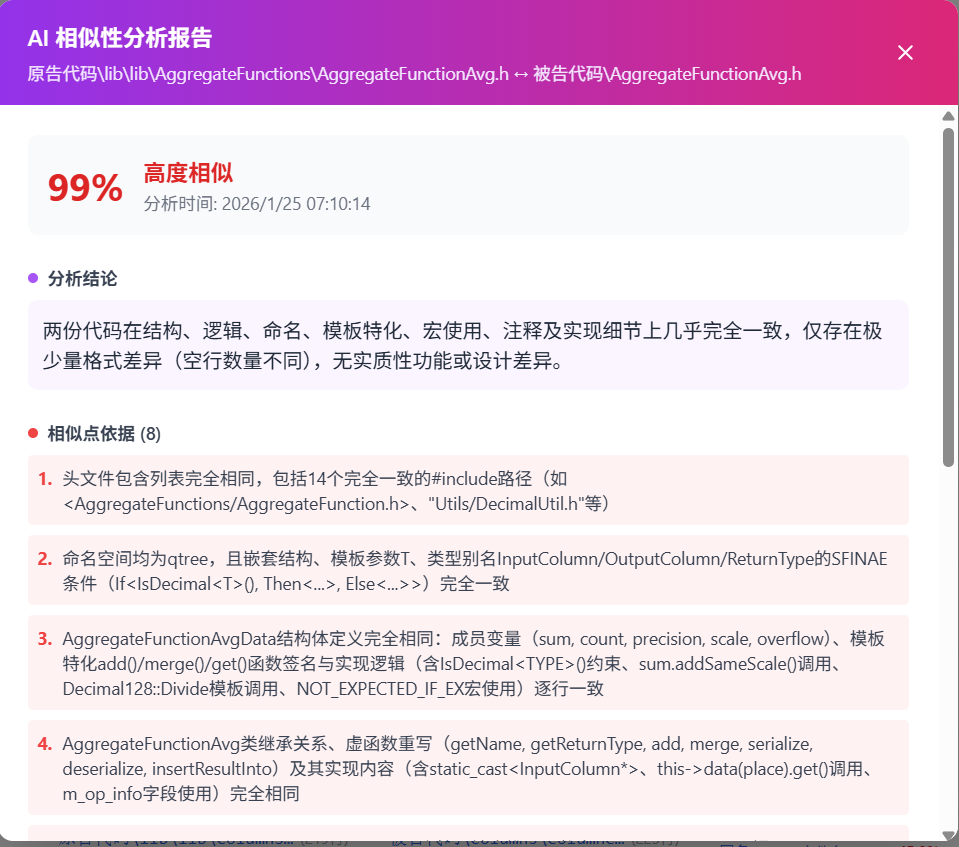
自动生成符合司法规范的鉴定意见书,每项结论均可追溯至具体代码片段与语义推理路径,确保结果透明、可审查、可质证。
核心优势
- 更准:基于深度语义理解,显著提升对“逻辑抄袭”等隐蔽侵权的识别能力,准确率远超传统工具。
- 更快:万行级代码分析可在分钟级完成,大幅压缩鉴定周期,助力司法高效裁决。
- 更公:全流程由大模型驱动,去主观化,保障鉴定结果的客观性与中立性。
- 更懂司法:内置司法鉴定规范与电子证据规则,输出格式严格对标法院采信标准。
应用场景
- 软件著作权侵权纠纷的技术鉴定
- 源代码泄露、员工离职盗用等取证场景
- 技术秘密同一性比对与商业秘密保护
- 开源代码合规性审查与许可证风险识别